Optimization #6747
opendpdk: synchronized CPU stalls on Suricata workers
Description
This is a report on trying to figure out why independent Suricata workers have the same access patterns to a Mellanox NIC. The debug tool that I am using is primarily Intel Vtune.
I am using 8 cores for packet processing, each core has an independent processing queue. All application cores are on the same NUMA node. Importantly, this only happens on Mellanox/NVIDIA NIC (currently MT2892 Family - mlx5) and NOT on X710. Suricata is compiled with DPDK (2 versions tested, replicated on both - master 1dcf69b211 (https://github.com/OISF/suricata/) and version with interrupt support (commit c822f66b - https://github.com/lukashino/suricata/commits/feat-power-saving-v4/)).
For packet generation I use the Trex packet generator on an independent server in ASTF mode with the command "start -f astf/http_simple.py -m 6000". The traffic exchanged between the two trex interfaces is mirrored on a switch to Suricata interface. That yields roughly 4.6 Gbps of traffic. The traffic is a simple http GET request yet the flows are alternating each iteration with an increment in an IP address. RSS then distributes the traffic evenly across all cores. The problem occurs both on 500 Mbps and on 20 Gbps transmit speed.
This is a flame graph from one of the runs. I wonder why CPUs have almost synchronous no CPU/some CPU activity in the graph below. The worker cores are denoted with "W#0..." and are in 2 groups that are alternating. CPU stalls can be especially seen in regions of high CPU activity but it is present also with low CPU activity. Having high/low CPU activity is not relevant here as I am only interested in the pattern of CPU stalls. It suggest for some shared resource. But even with a shared resource it would not be paused synchronously but randomly blocked.
I am debugging the application with interrupts enabled however the same pattern occurs when poll mode is enabled. When polling mode is active I filtered out mlx5 module activity from the Vtune result and was still able to see CPU pauses ranging from 0.5 to 1 second across all cores.
DPDK 8 cores, MLX5 NIC
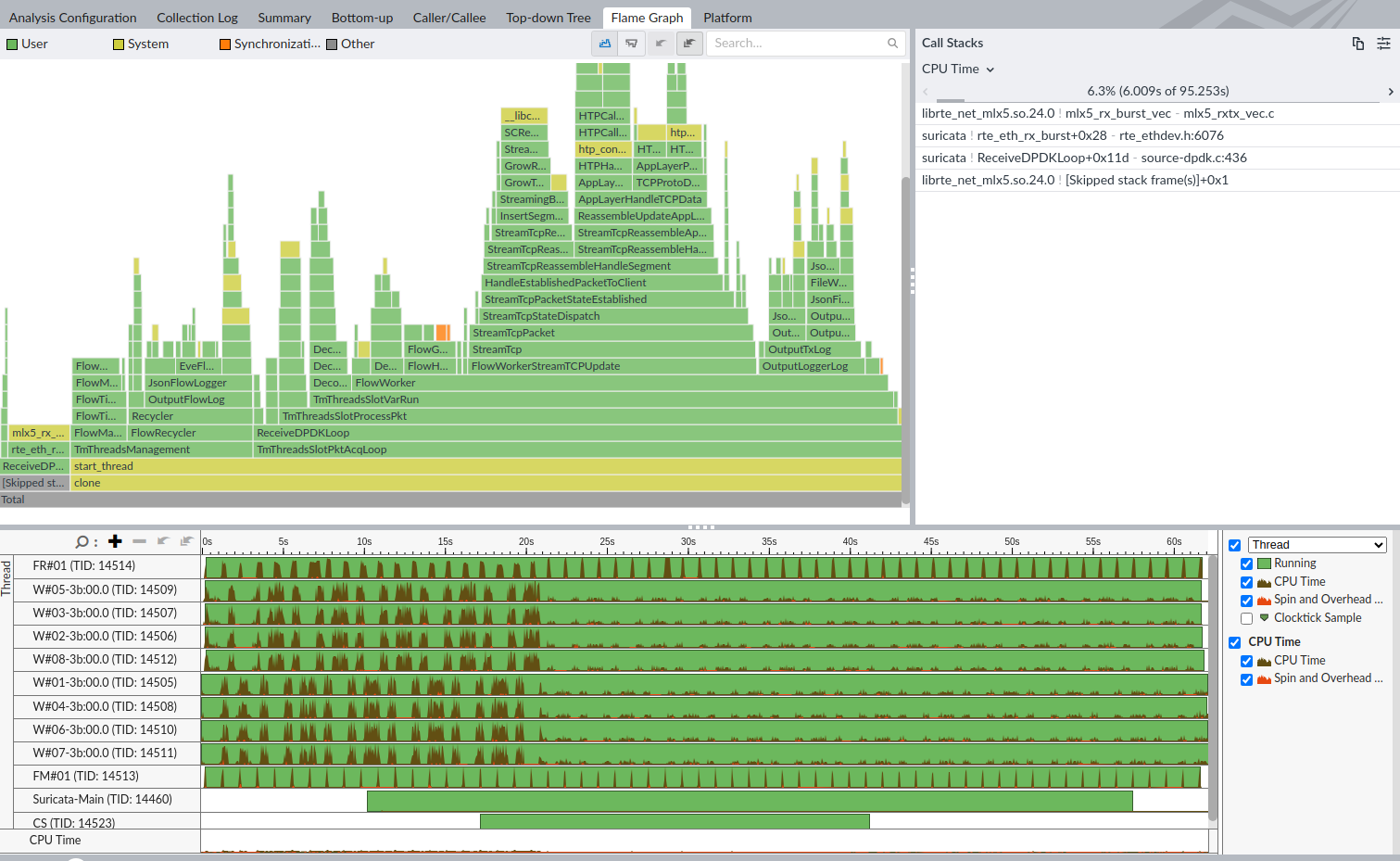
I tried to profile Suricata in different scenarios and this pattern of complete CPU stalls doesn't happen elsewhere.
e.g.
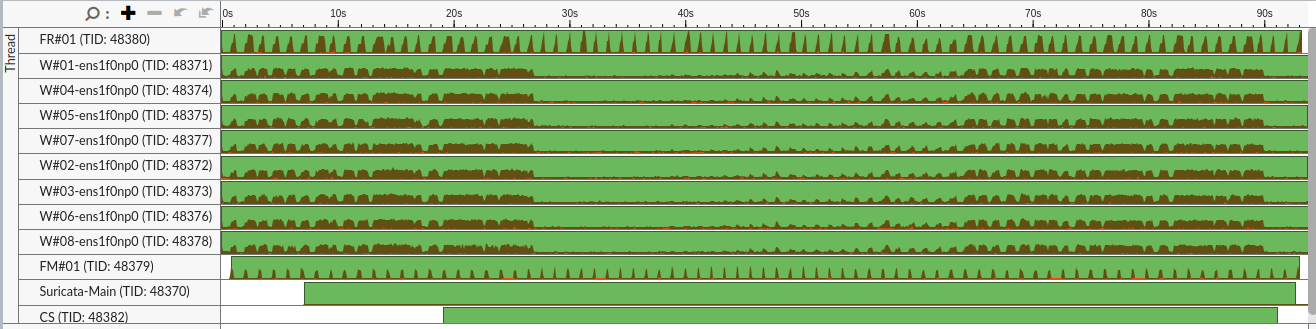
AF_PACKET 8 cores, MLX5 NIC, the CPU activity is similar across cores but the cores never pause:
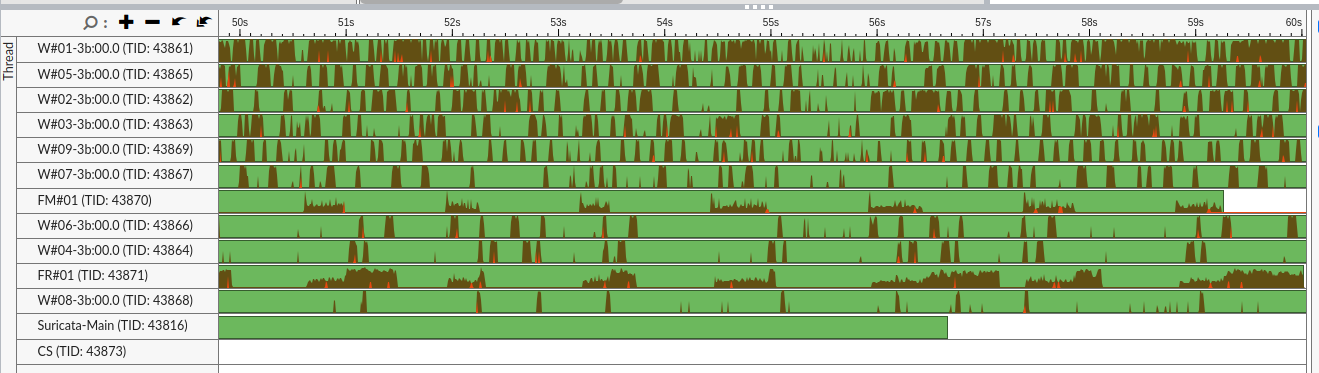
DPDK 4 cores, MLX5 NIC,

DPDK 9 cores, MLX5 NIC
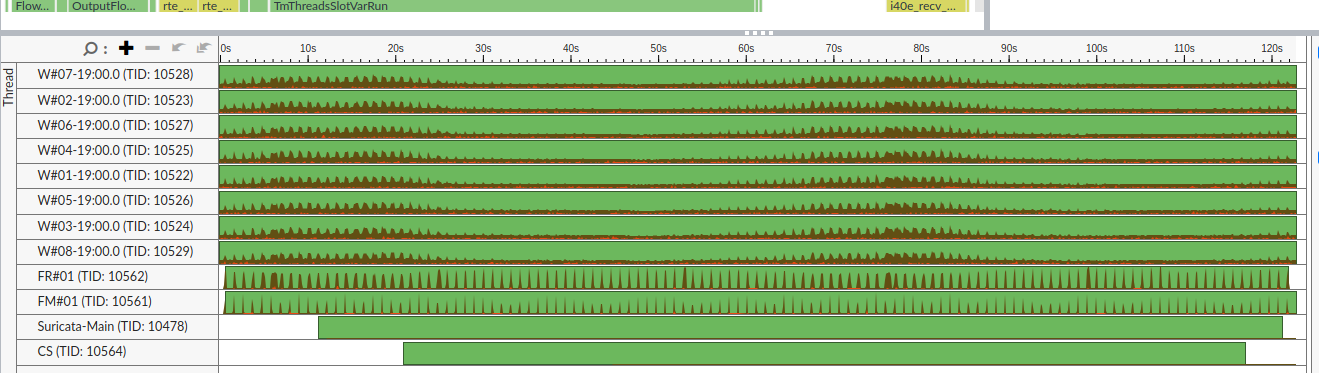
DPDK 8 cores, X710 NIC, no CPU stalls on worker cores
Testpmd, MLX5, 8 cores, I tried to filter out majority of RX NIC functions and it still seems that CPUs are being continuously active. (It was running in rxonly fwd mode, with 8 queues and 8 cores) Though I am a bit skeptical about the CPU activity as testpmd only receives/discards the traffic.
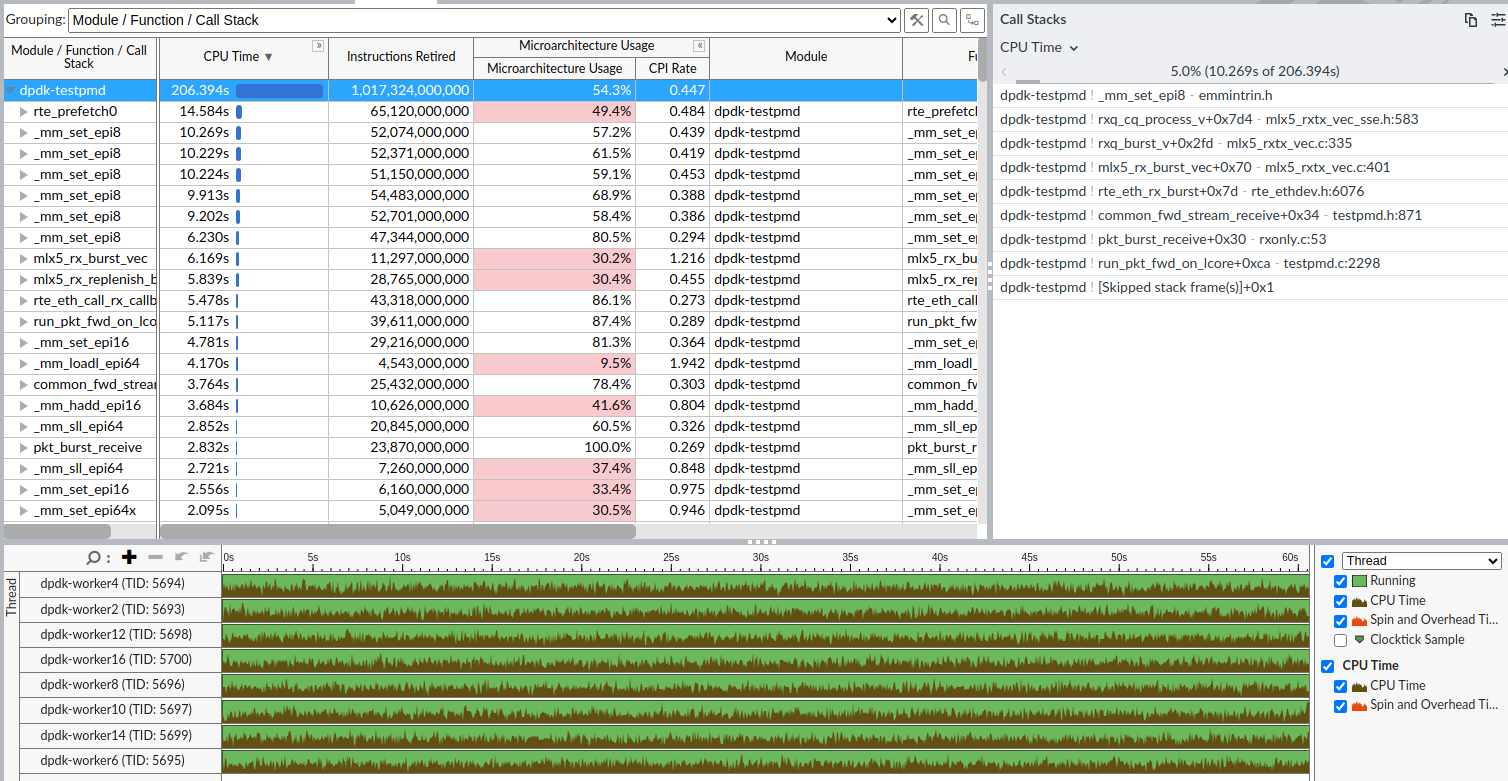
It seems like the issue is connected with MLX5 NIC and DPDK as it works well with AF_PACKET, and also with lower/higher number of threads.
Any input is greatly welcome.
Files
LS Updated by Lukas Sismis over 2 years ago
With regards to this I also come across two problems (unfortunately with no definitive answers):
1) AFP has better performance with the same amount of RX descriptors
2 ) DPDK doesn't scale well enough
1) AFP has better performance with the same amount of RX descriptors
AFP has however bigger buffers, so while it has e.g. 1k descriptors on the receive side (ethtool -g), it has ring/block/frame size 5 times bigger - When I e.g. started Suri but waited 10 seconds before the rx loop but after the port has started and I during that 10 secs I sent 20k packets I was still able to receive ~5k packets even though my descriptors were set to 1k. In DPDK it was almost exactly 1024 packets.
From the analysis, though it seems like the kernel fetches the packets off the nic to the buffer place. NIC should only be able to handle packet manipulation with those 1k descriptors, but receiving them and transferring them to the kernel buffer space.
Suggested solution:
add a secondary buffer to the DPDK implementation? Maybe it would be good to implement autofp runmode for cases when the number of RX descriptors is limited.
A little test proved to handle this situation better. It was a FIFO queue, where I fetched e.g. up to 32 packets from the NIC, pushed all of them to the FIFO queue (rte_ring) and then dequeued up to 16 packets only from the queue. In case of packet bursts, the worker was able to handle them while clearing the queue when the packet rate was lower. It would be however better to engineer a more elegant solution.
2 ) DPDK doesn't scale well enough
I run 4 core 16k rx desc Suricata and it performs better than 8 core 8k Suri. Why is that? I would assume as the traffic is split between cores then smaller number of descriptors will suffice
It additionally doesn't perform well enough even with 8c16k, in Vtune I can observe segments of CPUs going 100% and then 5%. And it alternates. Even with 8c16k, but also on 8c8k.
PA Updated by Philippe Antoine about 2 years ago
- Tracker changed from Support to Optimization
PA Updated by Philippe Antoine about 2 years ago
- Target version set to TBD
VJ Updated by Victor Julien over 1 year ago
- Target version changed from TBD to 9.0.0-beta1